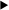| Issue 155 | August 23rd 2013 | Contact the Editor | How to Contribute |
|
| ||
|
Slaying the Unicode Monster I know you are keen to know how our development team is progressing with our various roadmap items. I thought it would be interesting to ask some individual developers to share with you their recent work. Today Ali Lloyd has agreed to take some of his valuable time to tell us about his work on unicode implementation. LiveCode is already being used in many different countries, and since going open source we are expecting to reach many more. Of central importance then is the ability of LiveCode-created apps to display a multitude of characters, ligatures and diacritics used in languages throughout the world. Currently, only a few elements of a LiveCode stack have this facility - for example tooltips and button labels - because the engine uses a special string class to store their text. But filenames and paths, names, and a plethora of other properties are stored internally as C strings. To see how to implement Unicode successfully in LiveCode as it stands at the moment, check out the Unicode Success article in this newsletter. Whilst most operations can be accomplished, the process is very far from our goal of "unicode, it just works". A C string is an encoding-agnostic entity - it is merely a pointer to an array of bytes, with a NULL char indicating where it finishes. Without any further information, when presented with an array of bytes one assumes that each byte represents a character. With 8 bits, that means only 256 characters are representable. The idea of unicode is that every possible character is mapped to a unique number. However, it would be extremely space-consuming to store every character using 32 bits- that would be using a lot of redundant zeroes for the standard ASCII character set.
Thanks to the ongoing syntax project, we already have the framework of an appropriate string class in place. Unfortunately to compare this to the slaying of the Nemean lion would be to extend the metaphor beyond breaking point, but suffice it to say that neither we nor Hercules can expect to achieve our ultimate goal if we have skipped the first step. So that's the task in a nutshell, but clearly it would be inefficient to search through the files alphabetically making the replacements. Ideally the task should be made modular and, most importantly, parallelizable. If Hercules had tackled the Hydra without having Iolaus at his side to prevent it from growing more heads, he would still be there now, exhausted and hacking away (although incidentally a very interesting theorem of mathematics states that given unlimited time, Hercules would still defeat the Hydra eventually). Unlike the worlds of mythology or abstract mathematics, ours sadly doesn't have unlimited time. The most potentially time-consuming part of scoping the unicodification is listing the engine methods whose signatures need to be changed so that unicode strings can pass through, untrammelled by the presumption that they use one byte per character. Luckily the LLVM compiler provides a call graph visualisation tool that expedites the process somewhat. If you're interested, the call graph of the LiveCode engine has over 13,000 vertices and 90,000 edges. It would require about 100 monitors side by side to display that graph at a legible resolution. So, while we wait for 80 new monitors to arrive at the RunRev offices, let's see if the process can be refined a little.
Well obviously we need only consider those methods that have string parameters. That reduces the graph to 840 vertices and 1000 edges. Quick, cancel 60 of those monitors! Moreover not everything need be updated. Old string constructors will stop being used, as will methods for which there already exist new string versions. After removing these, it becomes a case of simply extracting all the disjoint subgraphs (easily accomplished with a small LiveCode stack), giving an exhaustive list of the changes to be made; moreover they come already grouped in such a way that multiple developers can work through the subgraphs, safe in the knowledge that there will not be any merge conflicts. As a nice side-effect, we now have a quick tool for finding code that is never used and therefore should be deleted.
A section of the monster chart, click to zoom Once the LiveCode engine uses the new strings everywhere it needs to, the task boils down to making sure we call the unicode versions of methods in various platform APIs. Although we already have a reasonably comprehensive list of these, after the previous work, the places where new strings are converted to other types of string will have been pushed all the way down to the platform specific code, and we can simply observe where changes ought to be made. Currently we have two people in the first stages of the project. With a third joining them shortly, we should soon be making some serious headway. Meanwhile the syntax project is progressing nicely, and whilst its completion is unlikely to be in the immediate future, neither is it a long way off. We're working hard to get to our first DP which will be fully unicode-compatible, as well as containing the first phase of the syntax refactoring.
| 
Tweet
|

 Thus to enable the use of unicode throughout LiveCode, the engine will use a new string class which knows the encoding of its bytes, allowing them to be interpreted, communicated and displayed correctly. It improves upon the existing LiveCode string class by both being more flexible, and being a reference counted type- which means that memory allocated for a string is automatically freed when there are no more references to it. Replacing all the C strings in a source base as large as LiveCode's is a big job, somewhat akin to
Thus to enable the use of unicode throughout LiveCode, the engine will use a new string class which knows the encoding of its bytes, allowing them to be interpreted, communicated and displayed correctly. It improves upon the existing LiveCode string class by both being more flexible, and being a reference counted type- which means that memory allocated for a string is automatically freed when there are no more references to it. Replacing all the C strings in a source base as large as LiveCode's is a big job, somewhat akin to